
Drug discovery Manual
The combined approach of bioinformatics and chemoinformatics are helpful in drug designing process. Various chemoinformatics tools are applied in virtual screening, chemical dataset mining, and structure-activity relationship studies. Drug discovery process involves target identification and validation, lead identification, and lead optimization.
There are a number of computational tools and techniques which can be used at these specific sites. Here, the purpose of this manual is to give brief knowledge about how to use different chemoinformatics tools:
Whether it is chemoinformatics or bioinformatics, the information regarding drugs, the information regarding drugs, disease and their resources are the backbone of computer-aided drug discovery process. These informations are useful in developing knowledge-based models for discovering and designing new drug entities. The drug or disease related information can be extracted by using keywords e.g. full target name, drug name, disease name etc. Any other drug, disease or target related information can also be used for data searching. Following are few examples:
PubChem
Many times the chemical structures of compounds are not available or not in desired file format. In order to create the chemical structures with desired file format (e.g. SDF/MOL2 etc), a number of molecule editors can be utilized. ChemSketch: It is a drawing package that allows to draw and modify chemical structures. It can also used in calculating basic molecular properties. BKchem: It is a python-based editor tool that allows users to draw, edit, visualize the molecules and provide various options of structure modifications to the users. There are various chemical file formats available for describing any chemical's structure. Some most frequently used file formats are SDF, SMILES, MOL/MOL2 etc.
The molecule's physiochemical properties depends upon the specific conformation of the compounds. In order to select the desired compounds, suitable multi-conformer of chemical's structures are required. There are several tools for generating 2D/3D structures e.g. Obminimize option of OpenBabel tool can be used for energy minimization of the molecules.
Clustering of chemical compounds by structure or property-based similarity can be a powerful approach in drug discovery process, mainly in order to correlate the compound's pharmacological and physiochemical properties with the biological activity. Clustering tools are also used for diversity analysis for identifying structures in chemical libraries. Number of approaches have been used for clustering of chemical compounds e.g. the binary fingerprints based, graph properties based, maximum common substructure based etc. ChemMine, ChemMineR, Jcluster, ChemBioServer, ScaffoldHunter etc. are widely used clustering softwares. Molecular descriptor refers to the physical features of any chemical compound which is responsible for its physico-chemical propertites.Molecular descriptor calculation is a key step in classical quantitative structure-activity/property relationship (QSAR/QSPR) based modelling. It involves the encoding of a chemical compound in a vector of numerical descriptors. PaDEL, PowerMV, ODDesripotrs, Joelib, CDK etc are commonly used and freely available tools for descriptor calculation.
QSAR/QSPR is a process which quantitatively correlates structural molecular properties (descriptors) of compounds with their physiological functions (i.e. physicochemical properties, biological activities, toxicity, etc). It uses linear statistical methods such as Multiple Linear Regression, or non-linear methods e.g. Support Vector Machines (SVM), Artificial Neural Network (ANN), Decision Trees, Bayesian Classifier etc., to generate a mathematical model that connects experimental measures with a set of chemical descriptors.
Data Extraction (How to extract drug/diseases related information)
Data information can be extracted by following key words:
Molecule name- e.g. Erlotinib
Chemical name- e.g. Methoxycinchonidine, Erlotinib hydrochloride
Disease name- e.g. Malaria, Tuberculosis etc.
Target name- e.g. Protein Kinase, G-Protein coupled receptors etc.
Drug name- e.g. Tarceva, Quinine Dab etc.
Drug categories- e.g. Antimalarial, Analgesics etc.
Biological pathway.
Drug Dataset Sources (Major databases for drug/diseases related information)

DrugBank
ChEMBL

Therapeutic Target Database
Molecule editors
These molecule editors generally used to draw and manipulate chemical structures. They also having some other features e.g. geometry optimization, structure visualization, and energy minimization etc. Here, we are describing some commonly used editors:
MarvinSketch: MarvinSketch allows users to quickly draw molecules through basic functions on the GUI and advanced functionalities e.g. sprout drawing, customizable shortcuts etc.
Chemical file formats (How to read molecule files)
SDF file format: SDF stands for structure-data file and it is chemical data file format developed by MDL. Multiple compounds files are delimited by lines consisting of four dollar signs ($$$$). The compounds with this file format have extension as .sdf.
SMILES file format:The Simplified Molecular-Input Line-Entry System (SMILES) is a form of a line notation for describing the structure of chemical molecules. This format can be converted in 2D/3D conformation and have file extension as .smi.
Converting file formats: OpenBabel and JOELib are freely available open source tools for converting molecules between different file formats.
$ babel -i input_format input_file -o output_format output_file
Structure and geometry optimization of molecules
$ obminimize [OPTIONS] filename
Option:
-n: steps
-cg: Use conjugate gradients algorithm (default)
-ff: forcefield Select the forcefield
Chemical clustering
Molecular Descriptor calculation
Command for running PaDEL software
$ java -jar ~/Desktop/PaDEL-Descriptor
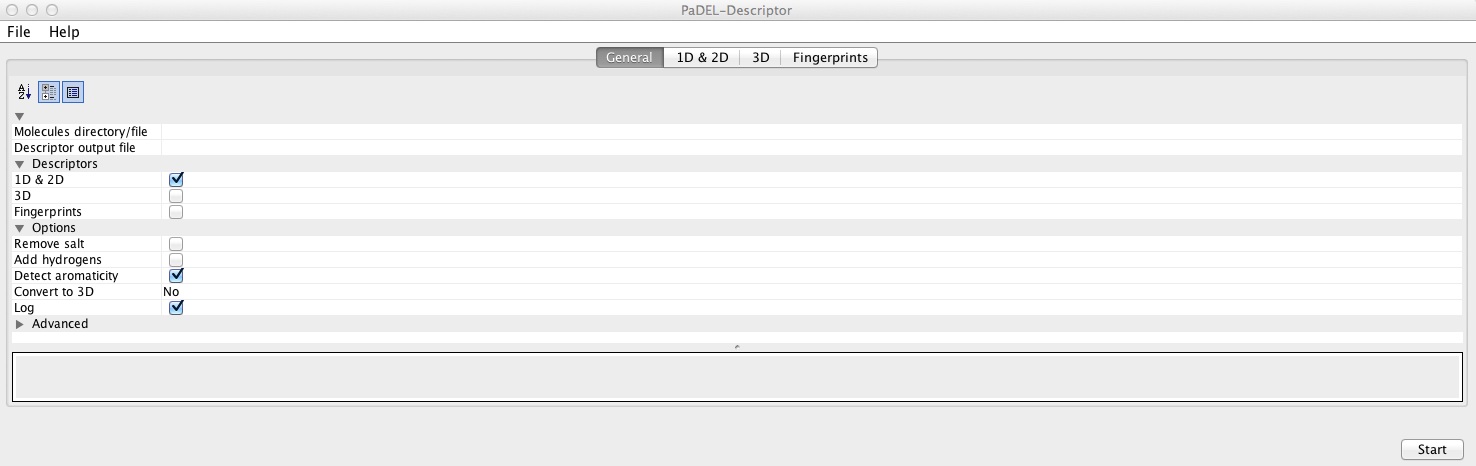
PaDEL command line usage:
$ java -jar PaDEL-Descriptor.jar -types of descriptors(2d/3d/fp) -dir input_directory having molecules -file output_file.csv
Development of QSAR/QSPR Models